Spam sms messages, the spam data which can lead to monetary losses.
In 2019, there is a 54.2% increase in scams vs 2018 which resulted in $168 million in losses. This represents an increase of $23 million from a year before.

We have observed that other crimes such as theft, housebreaking, crimes against other persons are dropping, but scams crimes have increased during the same period. Hmm… Is it possible for us to identify spam messages which lead to scams? By doing so, we can filter these spam messages and not to fall prey to these scams.
To do data science on human languages, we have to use the program natural language processing (NLP) to analyse words using computer. NLP would convert words to binary (i.e 1s and 0s) for the computer to understand. Thereafter, the computer would analyse the words and return to the user the analysis. We have downloaded the data from kaggle on sms messages from National University of Singapore (NUS). Click here to download the dataset. There are 5572 rows and 2 columns of data. By doing an exploratory data analysis, we can see that spam messages have longer words and non spam messages are shorter.

Over 77% of spam messages are above 100 words. While 90% of the non spam messages are below 100 words. This make sense as spam messages need to contain information for the recipient to take action. For example, an illegal money lender would share information on cheap loans using sms messaging and persuade recipients to sign up. Whereas non spam messages usually contain basic information on where to meet up, what food to eat and can be communicated with short messages.
Next, let us look into the key words found in these messages.

We have tokenise the spam words and non spam words to get those words which are used frequently. Spam words are likely to contain words like call, free, txt, claim, reply prize. While non spam words has words like, get, ill, call, come, got, like etc.
In data science, we would input these words into our models to decide which one is better. In fact, we can also used deep learning model such as recurrent neural network to check on how well it performs to detect spam messages.
To analyse the words for the models, we use TF-IDF (Term frequency — inverse document frequency). This TF-IDF determines how important a relevant word is in a document. Words that are not important are not included. For example words such as I, he, you are excluded, because it make no sense to include in the model for processing.

Our models shows support vector machines (SVM2) has the highest F1 score. SVM2 has a highest recall of 89% compared to the other models. Having a high recall would helps us get the most relevant results in the model. SVM2 is based on n-grams =2. The n-grams uses the TF-IDF word and the next word to work out the accuracy of the model.
Next, let us look at our deep learning model recurrent neural network (RNN). RNN is a deep learning algo using the sequence of inputs to analyse the data. We have to compute the training and accuracy scores as well as the F1 to see how our RNN model performs.
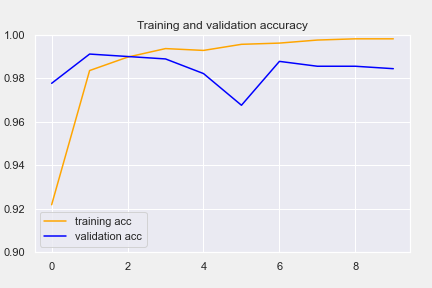

The training and validation data shows the RNN achieve over 98% training and validation accuracy and a loss of less than 10%. F1 score is 0.922. It means it has over 92% score to get an accurate assessment on the data.
Overall we can see SVM2 is still the best model i.e highest F1 score 0.928. As such, we will be using SVM2 to do a check on some sms messages.

By running a quick test on the model with some sms messages, we can see the model captures correctly the first 3 messages. Key words i.e in red boxes are spam data flagged in our model to label these messages as spam messages. The 4th message is not flagged as spam data, as it does not contain any key words found in spam data. As such, it is incorrectly classified as non spam data.
Therefore, in order to correctly classify spam data, we have to continue to build up a library of spam words. Spam words which contains money should be flagged and added with weighs in our model to increase their likelihood of labelling as spam and recipients of these messages should double check the authenticity with official sources.
If you have queries on the analysis, do connect me on linkedin. Click here.
To assess the code in github, click here
